
You've seen it happen. Maybe you've been the one standing in the conference room watching it happen.
The agent demo goes perfectly. Executives are nodding. Someone says "when can we deploy this?" And then — four weeks later, in actual production — the thing drops context mid-task, confidently outputs the wrong answer, or just silently fails while everyone assumes it succeeded.
One of those failures undoes everything the demos built.
That's not a prompt engineering problem. That's a trust destruction problem. And most teams don't see it coming until they're already in damage control.
What Agent Unreliability Actually Looks Like
Not all failures are dramatic. The subtle ones are worse.
Dropped context. The agent was tracking six things. Now it's tracking four. Nobody told it to forget the other two. It just did.
Hallucinated steps. The agent confidently reports it completed a task. The task wasn't completed. Or worse: it was "completed" in a way that's technically wrong but looks right until someone downstream catches the damage.
Silent failures. The agent encounters an edge case, doesn't know how to handle it, and instead of surfacing an error — it continues. Quietly. Producing outputs that look plausible and are subtly broken.
Inconsistent outputs. Same input, different outputs, no explanation. Fine for a toy. Unacceptable when a workflow depends on predictable behavior.
Each of these failure modes has something in common: they're invisible until they aren't. And by the time they're visible, the cost is already paid.
The Trust Destruction Mechanic
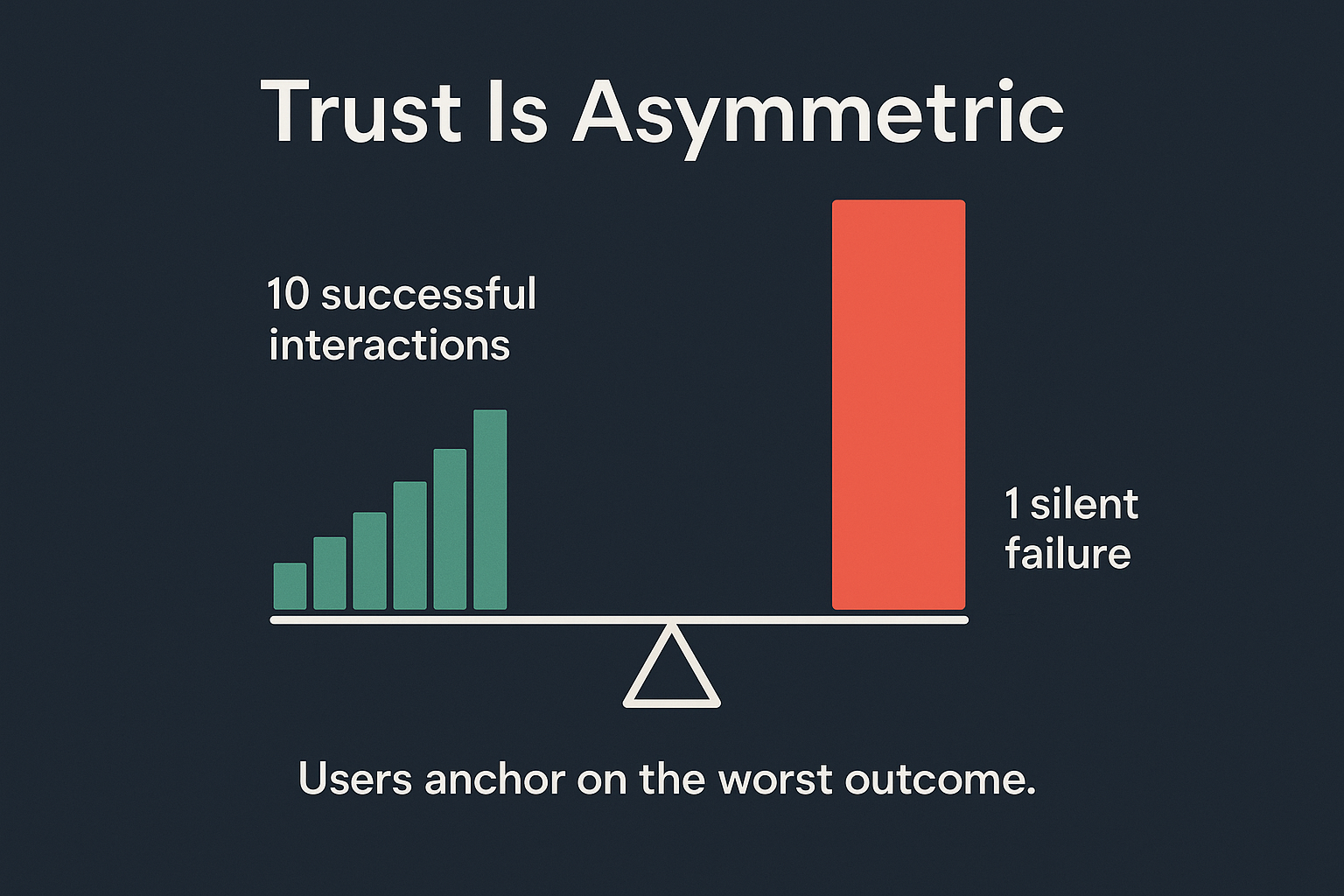
Here's what makes agent reliability different from other engineering problems: trust is asymmetric and it doesn't average.
You can run ten successful agent interactions in a row. One silent failure — one confidently-wrong output that someone acted on — and the mental model collapses. Users don't think "that agent is 90% reliable." They think "that agent can't be trusted with anything important."
This isn't irrationality. It's how human trust actually works. Loss aversion is real, and it applies to software: the pain of a bad outcome is felt more acutely than the satisfaction of a good one. With AI agents specifically, the bar is even higher — people are extending trust to a system that operates outside their line of sight. One violation and the whole premise breaks.
The result is predictable: teams quietly revert to manual workflows. Not because the agent was bad most of the time. Because they can't tell when it's going to be bad.
Why the Standard Fixes Don't Fix the Problem
Teams that hit the reliability wall usually reach for the same playbook:
Better prompting. More instructions, clearer constraints, more examples. This helps at the margins. It doesn't change the underlying behavior when the agent encounters something the prompt didn't anticipate — which is most real-world production traffic.
Retry logic. If it fails, run it again. Sometimes this works. Often it just runs the same failure twice and returns the second wrong answer with more confidence.
Human-in-the-loop patches. Add a review step here, a manual check there. Now you have a hybrid workflow that requires a human to babysit the agent everywhere it's most likely to fail — which is exactly what you built the agent to avoid.
These approaches have something in common: they treat symptoms. The agent is still non-deterministic at the system level. You're just building scaffolding around that non-determinism, and the scaffolding has its own failure modes.
The problem isn't the prompt. The problem is the absence of reliability infrastructure.

What Genuine Reliability Requires
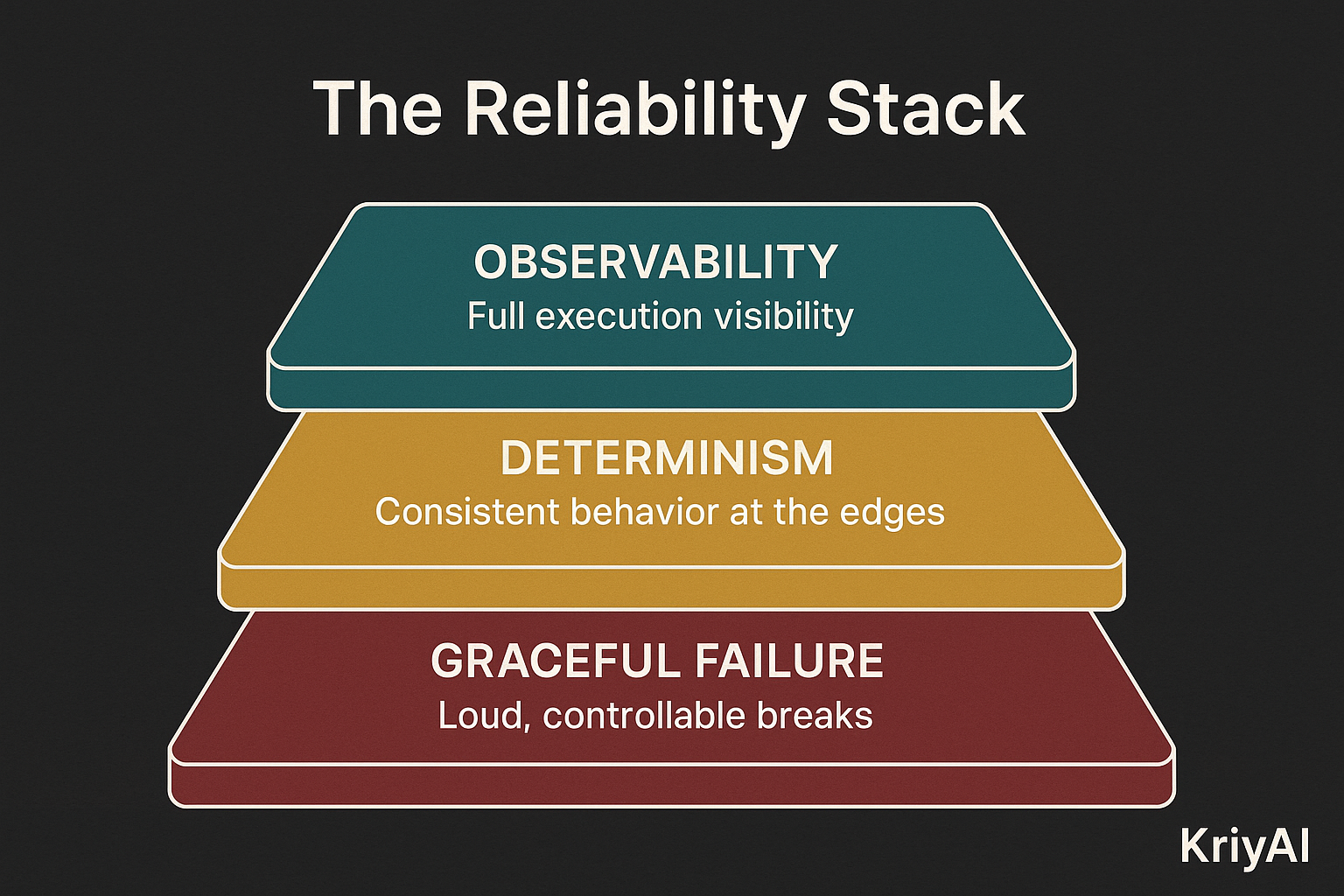
Real reliability isn't a prompt property. It's an engineering property. It has to be designed in from the system level.
Three components that can't be faked:
Observability. You need to know what your agent is doing and why — at the span level, not just the outcome level. When something fails, you need to know exactly where in the execution chain it failed, what state it was in, and what decision it made. Without this, you're debugging by guessing.
Determinism. Same inputs should produce predictably consistent behavior. Not identical — agents can be creative — but consistent in the ways that matter: scope adherence, error handling, output format, escalation logic. This requires deliberate design, not hope.
Graceful failure. When the agent encounters something it can't handle, it needs to break loudly and controllably. Not silently. Not confidently wrong. Surfacing uncertainty, stopping at a clear boundary, handing off to a human or a fallback — these behaviors have to be built in, not bolted on.
These aren't features you can ship in a patch. They're architectural properties. And they're what separate agents you can trust in production from agents that only work in demos.
A Different Engineering Posture
Most AI companies optimize for capability. What can the agent do? How impressive is the demo? How many integrations does it have?
KriyAI optimizes for reliability. What can the agent do consistently? What happens when it encounters something unexpected? How do you know what it's doing right now?
This isn't a philosophical position. It's a response to what we've seen in production. We've observed the failure patterns — dropped context, silent errors, inconsistent outputs — at scale, across real workloads. The patterns are predictable. The fixes are structural, not cosmetic.
The teams that succeed with AI agents in production aren't the ones who found the perfect prompt. They're the ones who built the infrastructure to catch, diagnose, and correct failures before they become trust violations.
That's the foundation KriyAI is built on.
The Real Question
The question isn't whether your agents will fail. They will. All complex systems do.
The question is whether you have the infrastructure to know when they fail, understand why, and improve — before your users lose confidence.
If the answer is no: you're not building AI products. You're managing a reliability gap that's going to catch up with you.